Introduction
As a participant of the Linux Kernel Mentorship (Fall) program, I was incentivized to find and fix kernel bugs reported by Google’s kernel fuzzer, syzkaller.
I picked net as one of my subsystems and decided to tackle the first bug I saw on the syzkaller dashboard. This naturally turned out to be a async-race monster.
The silver lining was that this forced me to learn a lot about the networking stack and a refactoring opportunity in net/core.
That’s exactly what I am going to talk about in the rest of the article.
Prerequisites
We need to know a few things before we can attempt to explain the solution. This section covers those prerequisites. Feel free to skip it if you already understand them.
Running a Custom Kernel
If you are going to modify the linux kernel, you would want to be able to run it. Thankfully, the overall process is conceptually simple. Let’s start with the “running” part.
To run a modified kernel, we need two things: a disk image and a kernel image (bzImage). This assumes that we have QEMU installed, but we’ll get to that in a bit.
The disk image serves as the storage for our environment. You can either create one or obtain it from somewhere. If you don’t know where to start, I suggest using a Debian nocloud image, which this article assumes. Reusing the disk image provided by syzkaller for your bug also works.
bzImage is the kernel image generated by the Linux compilation process. For x86 and x86_64, it is always generated as arch/x86/boot/bzImage.
Now, Let’s get to QEMU.
QEMU
QEMU is a generic and open-source machine emulator and virtualizer. QEMU is a major component of most virtualization software.
We will use QEMU to set up an environment suitable for testing our changes.
The QEMU executable differs by architecture and is usually named qemu-system-$(ARCH). For this specific bug, qemu-system-x86_64 is sufficient.
Now that we have everything we need, we can create our instance by running:
qemu-system-x86_64 \
-m 2G \
-smp 16 \
-kernel ./bzImage -append "root=/dev/vda1 console=ttyS0 earlyprintk=serial" \
-drive file=debian-12-nocloud.qcow2,format=qcow2,if=virtio \
-nic user,model=virtio-net-pci,hostfwd=tcp:127.0.0.1:10021-:22 \
-enable-kvm -nographic -snapshot
Check the VIRTIO_ options in your .config if your instance is unable to mount the disk.
If you wish to use GDB to debug the crash, append -s -S to the command. This starts a GDB server instance on port 1234 and waits for kgdb to start.
That’s gonna be our next section.
Kernel GDB
Kernel GDB works like remote GDB, except the executable you are debugging is the Linux kernel itself. After you connect to the GDB server exposed by the QEMU instance, it behaves just like regular GDB.
The only caveat is that you need an artifact called vmlinux to understand kernel symbols. This is generated during kernel compilation in the base directory as vmlinux.
For a complete description of KGDB, consult this document.
Compiling the Custom Kernel
Now that we understand the artifacts we need, we should know how to generate them.
First, we need a config file. You can either copy one (recommended for syzkaller bug hunting) or generate one by running a make command depending on your needs. The most basic commands are:
# Either
make olddefconfig # make oldconfig + fills in the defaults
# Or
make localmodconfig # creates a config based on the current config and loaded modules
Before that, clean up everything by running
make mrproper # Delete artifacts and old config
Then build the kernel:
make -j$(nproc) # Runs make with $(nproc) cores
This gets us the necessary artifacts.
Syzkaller
Syzkaller is Google’s kernel fuzzer, as mentioned in the intro. You can set it up on your local system by following the instructions in the repo. However, We will be using syzbot for bug hunting.
Syzbot is a CI/CD tool built on top of syzkaller. For the exact differences, please refer to this discussion
Google hosts a syzbot dashboard here. You can search for bugs per subsystem on the subsystem page.
For each crash of a reported bug, syzkaller provides a config, a disk image, a vmlinux, a bzImage, and a reproducer if it exists. I suggest using the artifacts from the most recent crash.
If a reproducer is provided, you can trigger the crash by running it. You might be wondering how QEMU emulates USB devices. For that, I suggest watching this video on the raw-gadget framework.
These artifacts are useful only for reviewing the code as it exists. If you change something, you need to generate your own artifacts. I suggest using the provided artifacts to check whether a bug is consistently reproducible. If it is not, consider picking a different bug — this will save time that would otherwise be wasted on a hard-to-reproduce issue.
You can say with reasonable confidence that a bug has been fixed if the reproducer no longer triggers the crash after your changes and if your fix makes logical sense. Depending on the bug, a real human tester may still be necessary — as was the case for this bug.
Solving the bug
This will be done in multiple passes.
Pass 1
The USB part
Looking at the dashboard, the first thing that should come to your mind is that the USB core is involved here. Looking at the crash report, you can see that a URB was submitted while it was still active. The natural question is of course: What the heck is a URB?
A URB (USB Request Block) is essentially the complete execution context required for one USB transaction. You can read more about it in the documentation here.
A URB is filled by the caller and passed to the USB core, which then uses it to perform the corresponding USB transaction. URBs may be reused only after the completion handler finishes executing. In our case, the flow looks like this:

write_bulk_callback is the completion handler here. It’s the function that will run after the URB transaction completes.
If you look at the driver, you’ll notice that it maintains exactly one URB (tx_urb) for start_xmit for its entire lifetime. The bug arises because this URB is being reused too early, i.e., before the ongoing TX completes.
With that understanding, let’s look at similar bugs in other drivers to get a sense of what to expect.
Attempt 1
I decided to search through fixed bugs using the search term “submit_urb”. It turns out most of the bugs of form WARNING in x_submit_urb were errors caused by improper endpoint checking.
Eventually, however, I found this bug and it looked similar enough to ours. At this point, I convinced myself that the problem was in the TX timeout handler.

My reasoning was that usb_unlink_urb() did not kill the URB as:

So, I tried replacing usb_link_urb() with usb_kill_urb() and checked if it fixed the bug.
It did not in fact do that.
Pass 2
Since that did not work out, I decided to try predicting when the crash happens. What I learnt is that the crash is utterly unpredictable. Sometimes it happened within 30 seconds. Other times, it took 30-45 minutes.
Since that seemed hopeless, I decided to add prints in all the functions that looked relevant. These were
write_bulk_callback()rtl8150_start_xmit()rtl8150_open()rtl8150_close()
This turned out to not be very useful.
However, around this point of time, I started to find netif_{start/stop/wake}_queue functions suspicious. Intuitively, they start/stop/resume the TX packet queue.
I also suspected rtl8150_set_multicast() was suspicious but this was a stretch. So, I added prints inside them.

Aha — Here’s the pattern we are looking for.
Whenever the crash happens, a call to rtl8150_set_multicast() is always present right before it. And whenever that call is missing, there is no crash.
Therefore, that function is the key to this bug.
So let’s look at the code.
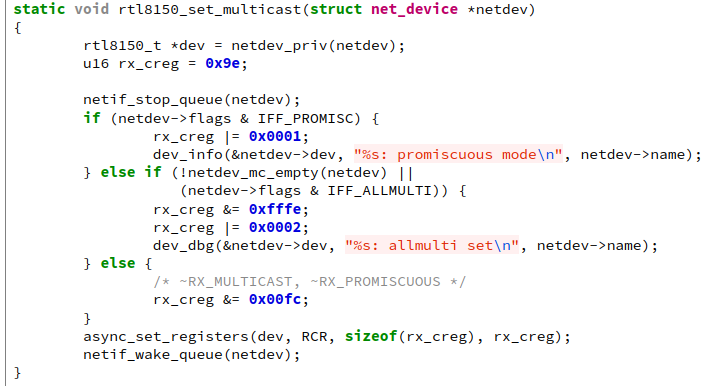
Well… we aren’t ready yet. We need to understand TX flow in net to make complete sense of the bug.
The net part
The TX flow technically begins at send(), when userspace hands data to the kernel. But for brevity’s sake, we skip the socket and protocol-stack processing and jump straight to the point where packets are handed to the device layer: dev_hard_start_xmit().
After enough processing, the control flow looks like this:
send()
...
dev_hard_start_xmit()
xmit_one()
netdev_start_xmit()
__netdev_start_xmit()
ops->ndo_start_xmit()
Eventually, we reach dev_hard_start_xmit(), which invokes the driver’s implementation of ndo_start_xmit callback.
If you inspect this call chain, one thing stands out: none of these functions enforce TX flow control themselves.
This is by design. That responsibility is left to the drivers.
dev_hard_start_xmit() just pushes the packets one at a time to the lower layers and checks whether the TX queue has been stopped. If it has been stopped, it doesn’t push any more packets.
The actual TX work happens in the driver-specific ndo_start_xmit() callback. In addition to processing and transmitting packets, this callback is responsible for TX flow control, which depends on device capabilities and hardware state. TX flow control is implemented using:
-
netif_stop_queue(dev)– tells the core to stop sending new packets / stops the TX queue -
netif_wake_queue(dev)– tells the core to resume sending / wakes up the TX queue -
netif_start_queue(dev)– used for initial activation / starts the TX queue.
Given this information, let’s go back to our problem child.
Attempt 2
Looking at rtl8150_set_multicast() and logs again:
We see that rtl8150_set_multicast() prematurely wakes up the TX queue before the rtl8150_start_xmit() finishes processing the request. This makes absolutely no sense as the set_rx_mode() callback has no business with TX queues.
This is the reconstructed sequence of events:
// CPU0 (in rtl8150_start_xmit) CPU1 (in rtl8150_start_xmit) CPU2 (in rtl8150_set_multicast)
netif_stop_queue();
netif_stop_queue();
usb_submit_urb();
netif_wake_queue(); <-- Wakes up TX queue before it is ready
netif_stop_queue();
usb_submit_urb(); <-- Warning
URB Completion
With this in mind, the fix is removing those disruptive calls from the set_rx_mode callback. This is what I did and it fixed the bug.
After you fix the bug locally, you should mail it to the bot that reported it to verify your patch on Google’s syzbot instance. This is what that looks like:
Mailing the patch
An Expected Beginning
Solving the bug is just one part of the picture; the patch should withstand scrutiny from maintainers and reviewers. Here’s the v1 I submitted
I expected a response in about a week or so considering how slow kernel development is. To my (pleasant) surprise, it took 8 hrs. This made me realize that net is actually a very fast moving subsystem.
The response was

Yikes, That’s something I forgot to take into account. Thankfully the Network Devices, the Kernel, and You! page clarifies this

The RX mode synchronization is handled entirely by netif_addr_lock(). I replied with this explanation and Andrew accepted it and asked me to incorporate
this into the commit message in v2. Here’s the v2.
An Unexpected Development
I was expecting comments on my patch. What I was not expecting was this.

I forgot to mention (or perhaps it was obvious from the title): this driver is from the pre Git era. This is probably a reasonable response for a legacy driver targeting a device that was supposed to be obsolete 20 years ago.
Panicking a bit, I prepared and mailed a patch to delete the driver, linked here. This broke build, and thankfully, I didn’t have to fix it.
Testing
Turns out, testing with syzkaller was insufficient, which explains Jakub’s response. Thankfully, Michal Pecio had a rtl8150 and volunteered to test the patch.
He triggered the bug by running:
# This is instantly triggered on HW simply by running:
ncat remote-host port < /dev/zero &
ifconfig ethX allmulti
Michal pointed out that my original description was unnecessarily complex. The following event sequence is sufficient to trigger the bug:
rtl8150_start_xmit() {
netif_stop_queue();
usb_submit_urb(dev->tx_urb);
}
rtl8150_set_multicast() {
netif_stop_queue();
netif_wake_queue(); // <-- wakes up TX queue before URB is done
}
rtl8150_start_xmit() {
netif_stop_queue();
usb_submit_urb(dev->tx_urb); // <-- double submission
}
He also confirmed that my patch prevented the bug from triggering.
Taking this into account, I submitted v3 here
Petko Manolov, the maintainer of this driver, ok’ed my change after everything settled down.
v3 got applied into netdev/net.git (main) and eventually ended up in mainline.
The commit is 958baf5eaee3(“net: usb: Remove disruptive netif_wake_queue in rtl8150_set_multicast”). You can find the metadata for this patch
here.
Closing Remarks
Credits to Michal Pecio michal.pecio@gmail.com for testing this patch and Thanks to Jakub, Andrew and other netdev maintainers for being incredibly professional and helpful.
That was an experience. After everything settled down, I decided to go back and have a look at a reply that seemed interesting to me
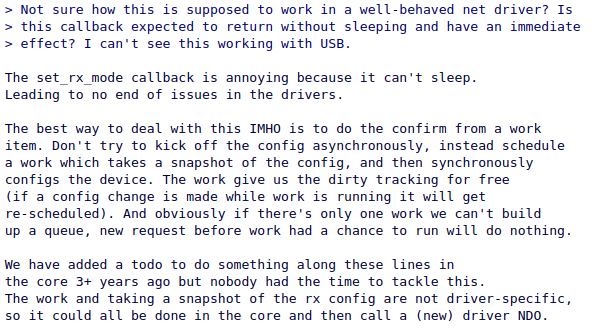
I am currently working on this at the moment and so far, Jakub seems to be fine with me implementing it.
Once again, I would like to reiterate that this was an invaluable experience in debugging, kernel development, and upstream submission.
I know this article isn’t the most beginner friendly. For that, I would recommend Javier’s blog, which I found extremely invaluable.
Thanks for reading.